| Exponential function | \(e^{ax}\) | \(x\in \mathbb{R}, a \in \mathbb{R}\) | Growth processes and failure probabilities |
| Neg. logarithm | \(-\log x\) | \(x > 0\) | Probability distributions |
| Linear functional | \(c^T x\) | \(x\in \mathbb{R}^n, c \in \mathbb{R}^n\) | Combination of effects |
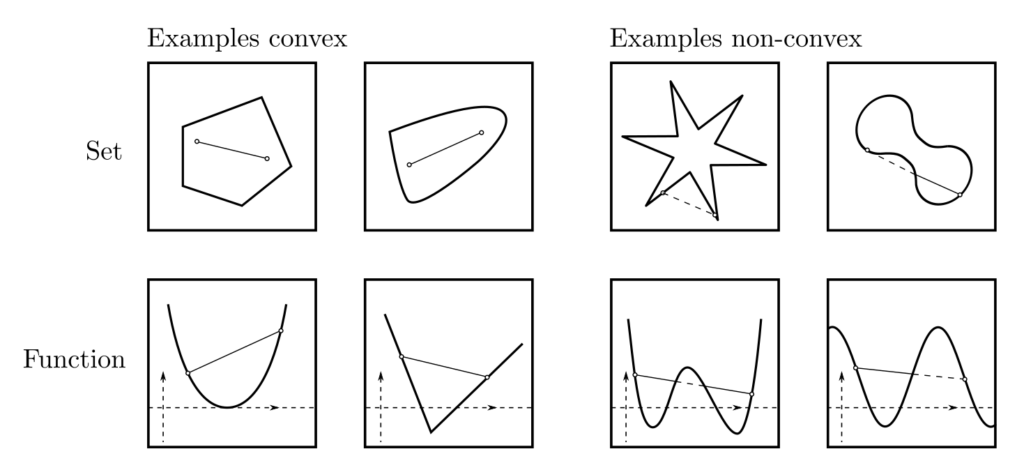
| Norm | \(\|x\|_p\) | \(x \in \mathbb{R}^n, p \ge 1\) | Discrepancies and distances |
| Neg. entropy | \(-\sum_{k=1}^n p(x_k)\log p(x_k) \) | \(p(x_k)> 0\) | Comparison probability distributions |
| Neg. geom. mean | \( — \left(\Pi_{k=1}^n x_k\right)^{1/n}\) | \( x\in \mathbb{R}^n, x_k >0\) | Growth processes and indicator functions |
| Maximum | \(\max (x_1, …, x_n)\) | \( x\in \mathbb{R}^n\) | Unproportional impacts |
| Softmax | \(\log \left( \sum_{k=1}^n e^{x_k}\right)\) | \( x\in \mathbb{R}^n\) | Machine learning |
| Neg. logdet | \(- \log \det X\) | \(X\) positiv definite | Covariance matrices and energies |
| Sum of eigenvalues | \( \sum_{k=1}^n \lambda_k(X)\) | \(X\) positiv semidefinite | Uncertainties and distributional properties |
| Matrix fractional | \(x^YP^{-1}x\) | \( x\in \mathbb{R}^n, P\) positiv semidefinite | Normal distributions and anisotropic distances |