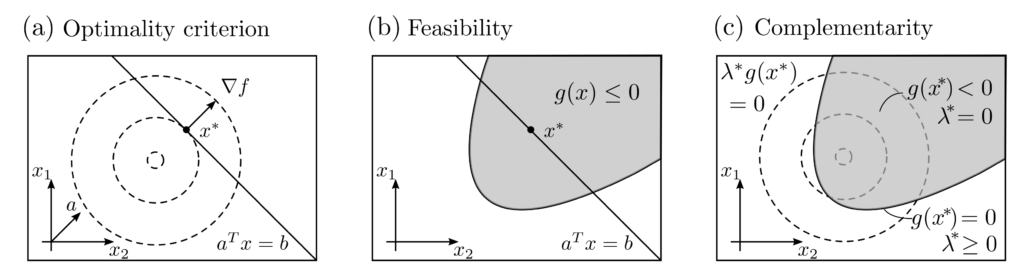
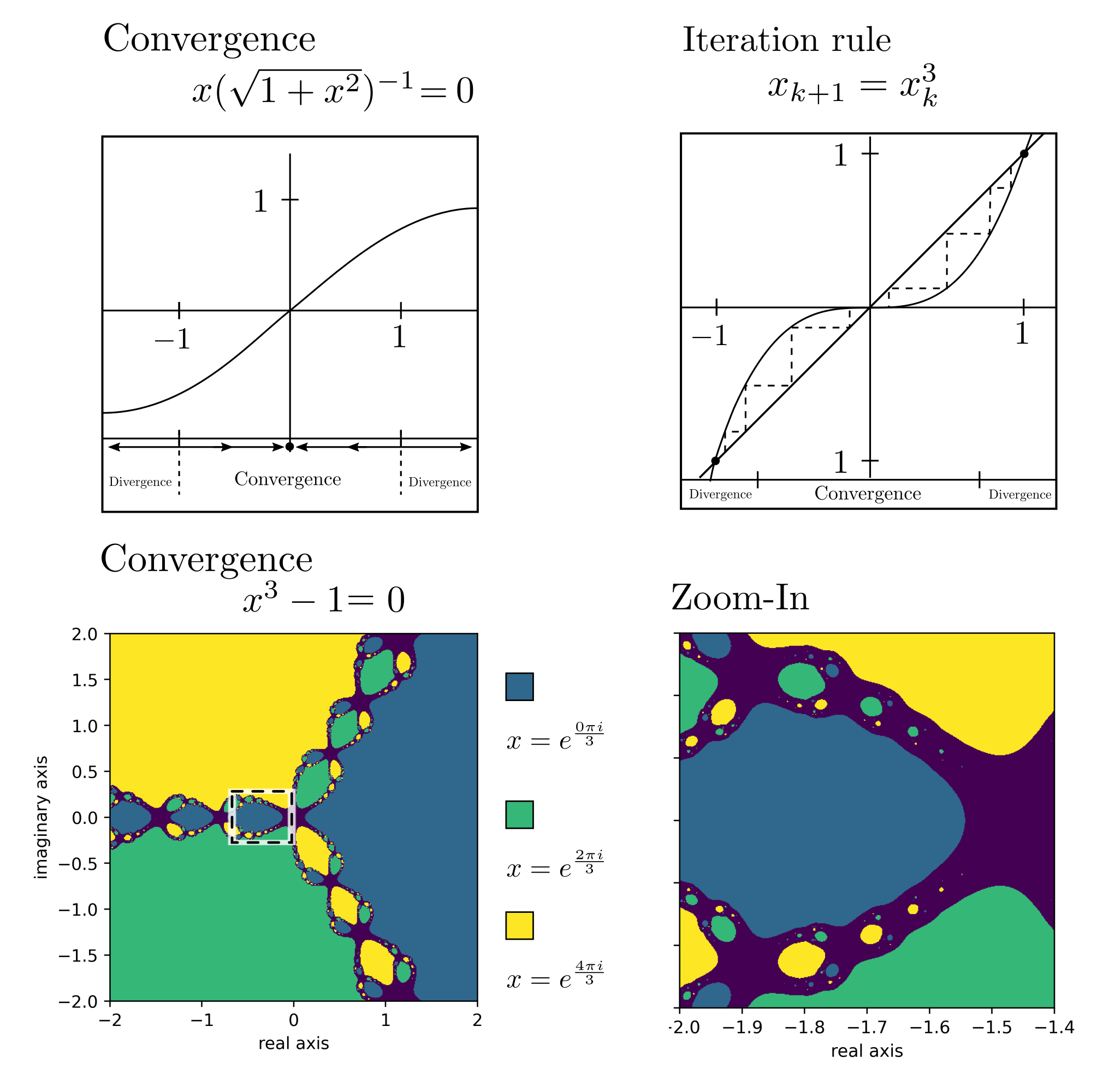
Example code: Theory_newton_convergence.py in our tutorialfolder
[1] Boyd, S., & Vandenberghe, L. (2004). Convex Optimization. Cambridge: Cambridge University Press.
[2] Mehrotra, S. (1992). On the implementation of a primal-dual interior point method. SIAM Journal on Optimization. 2 (4): 575–601.
[3] Nesterov, Y. (2013). Introductory Lectures on Convex Optimization: A Basic Course. Berlin Heidelberg: Springer Science & Business Media.
[4] Sternberg, S. (2014). Dynamical Systems. New York: Courier Corporation.
[5] Butt, J.A. (2019). An RKHS approach to modelling and inference for spatiotemporal geodetic data with applications to terrestrial radar interferometry. Dissertation ETH Zürich, Zürich.
[6] Harris, C.R., Millman, K.J., van der Walt, S.J., Gommers, R., Virtanen, P., Cornapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N.J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M.H., Brett, M., Haldane, A., Fernandez del Rio, J., Wiebe, M., Peterson, P., Gerard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abbasi, H., Gohle, C., & Oliphant T.E. (2020). Array programming with NumPy. Nature, Vol 585, No. 7825.