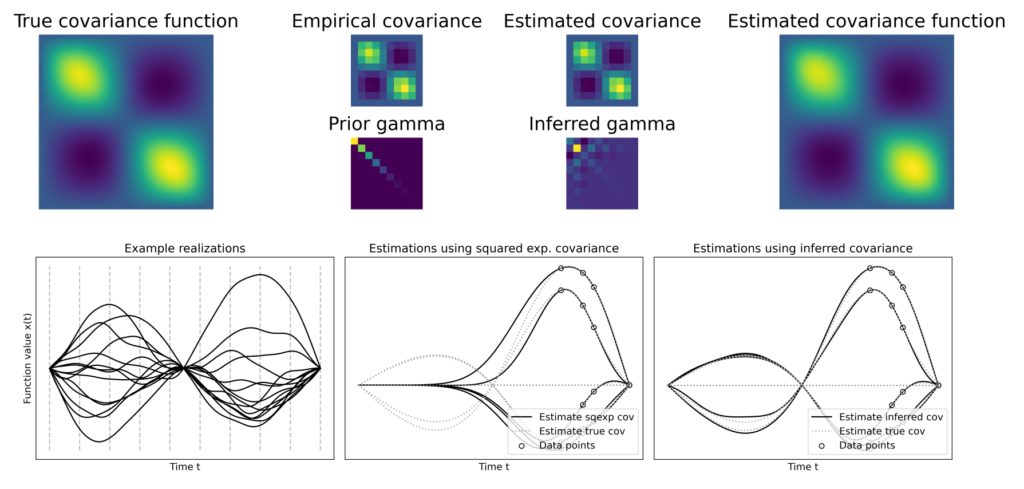
Assuming \(K(z_1,z_2)\) is a square \(B^TB = \int_Z B(z_1,z)B(z,z_2)dz\) of normally distributed random functions \(B\), then \(\gamma\) is approximately Wishart distributed. With \(p(l|\gamma)\) being the conditional probability of observations \(l\) given the covariance function dependent on \(\gamma\) and \(p(\gamma)\) the probability of \(\gamma\), according to Bayes’ theorem,
$$p(\gamma|l) = c p(l|\gamma)p(\gamma) ~~~~~~ c \text{ a constant}.$$
Here, \(p(\gamma|l)\) is the conditional probability of \(\gamma\) when \(l\) has been observed. Maximizing the probability is equivalent to minimizing \(-\log p(\gamma|l)=-\log p(l|\gamma)-\log p(\gamma)\).
The optimization problem is formulated as
$$ \begin{align} \min_{\gamma} ~~~& \log \det C_{\gamma} + \operatorname{tr} (SC_{\gamma}^+)+ r\left[ — \log \det \gamma + \operatorname{tr}(\Lambda^+\gamma)\right] \\ \text{s.t.}
~~~& A \gamma =b \\ ~~~& \gamma \succeq 0 \end{align}$$
where \(S\) is the empirical covariance matrix of the data \(l\), \(C_{\gamma}\) is the covariance matrix reconstructed using \(\gamma\), \(C_{\gamma}^+\) its pseudoinverse, and \(\Lambda\) a matrix encoding a‑priori assumptions about \(\gamma\). The regularization constant \(r\) balances prior knowledge and data, and \(A \gamma = b\) are linear conditions for \(\gamma\) representing definite knowledge about underlying correlations. With information about first and second derivatives of the objective function, the following numerical scheme emerges [2, p. 194]
$$ \begin{align} \gamma &= \gamma +\Delta \gamma ‑A^T(A\gamma A^T)^+A\Delta \gamma \\ \Delta \gamma & = \frac{1}{1+r} \left[ (r‑1)\gamma +S_{\psi} — r\gamma \Lambda^+\gamma\right] \end{align}$$
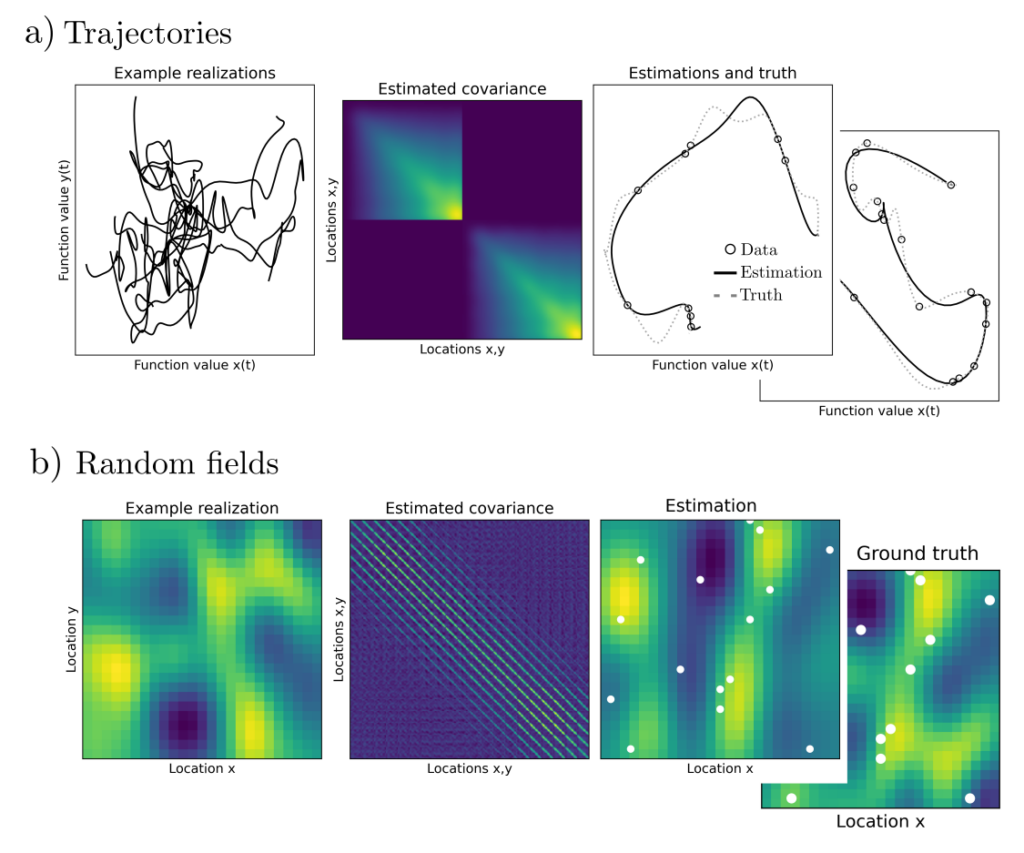
where \(S_{\psi}\) is a transformed version of the empirical covariance matrix. When iterations over \(\gamma\) are numerically stabilized and carried out to convergence, the result is a covariance function \( K(z_1,z_2)\) constructed using \(\gamma\). This predicts for all possible positions \(z_1, z_2\) the associated correlations ensuring they are maximally consistent with the point observations \(l\) and the prior assumptions.