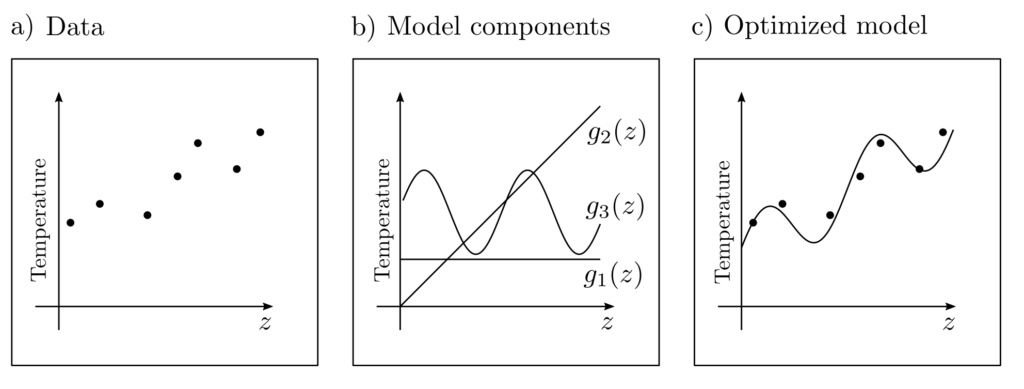
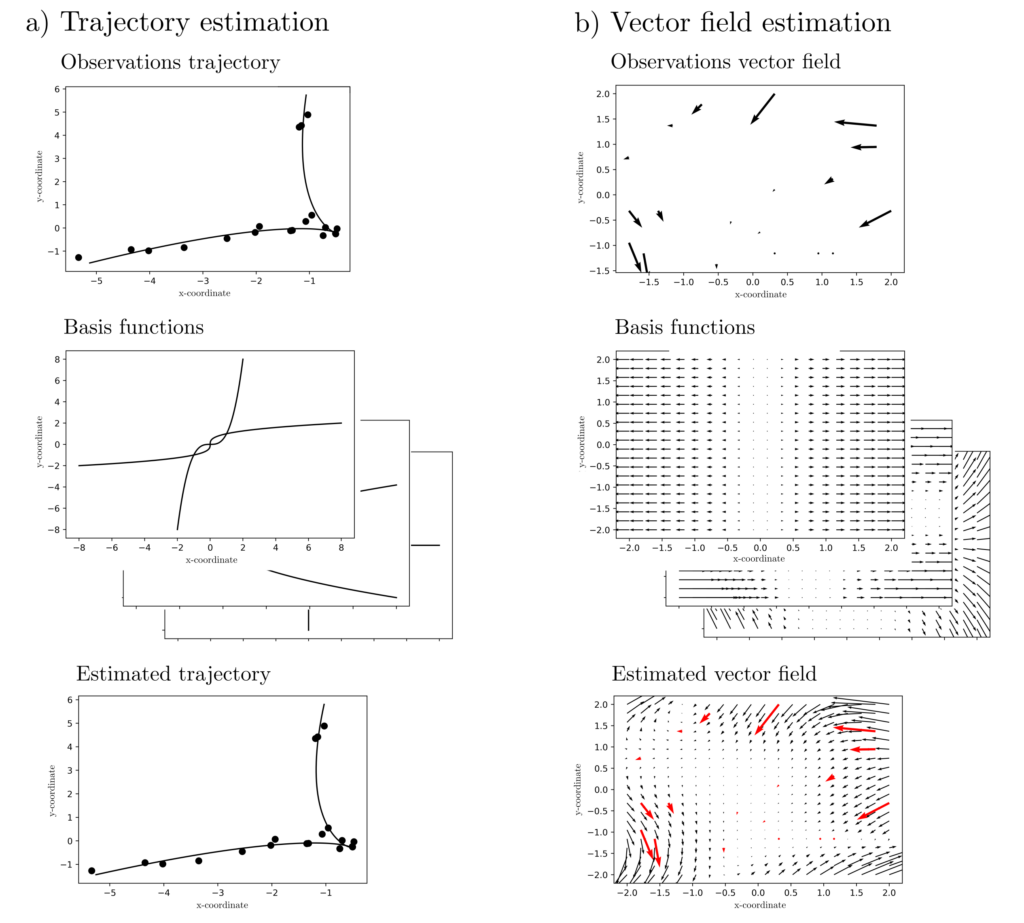
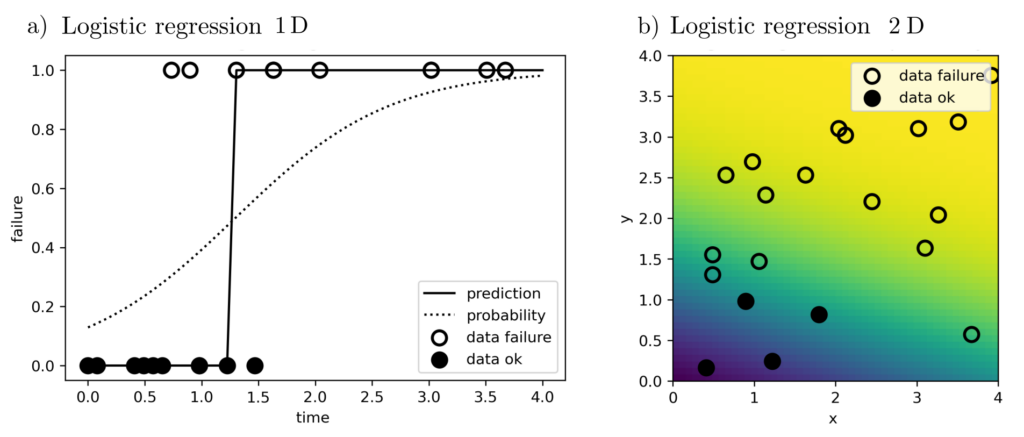
The previous formulations contain quadratic objective functions of the form \(\sum_{k=1}^n \|l_k‑g(x,z_k)\|_2^2\) and are thus least-squares problems. Minimizing these objective functions is sensible when the model class \(g(x,z)=\sum_{k=1}^m x_mg_m(z)\) can completely explain the data except for (standard) normally distributed residuals \(\epsilon\). Then it holds that
$$ l_k=g(x,z_k)+\epsilon_k \Leftrightarrow \epsilon_k= l_k‑g(x,z_k). $$
The probabilities of the residuals \(\epsilon_1, …, \epsilon_n\) are then \(p(\epsilon_k)= (2 \sqrt{\pi})^{-1} \exp\left( — \frac{1}{2} \epsilon_k^2\right)\). The probability of the occurrence of all residuals \(\epsilon_1, …, \epsilon_n\) together is
$$ p(\epsilon_1, …, \epsilon_n)=\prod_{k=1}^n p(\epsilon_k) = (2^n \pi^{n/2})^{-1} \exp\left( -\frac{1}{2} \sum_{k=1}^n \epsilon_k^2 \right)$$ for statistically independent residuals \(\epsilon_k \coprod \epsilon_j, k \neq j\). A choice of \(x\) such that all the residuals \(\epsilon_1= l_1‑g(x,z_1), …, \epsilon_n=l_n‑g(x,z_n)\) are as probable as possible leads to
$$ \max_x p(\epsilon_1, …, \epsilon_n) \Leftrightarrow \min_x \sum_{k=1}^n \left(l_k‑g(x,z_k)\right)^2. $$
The previous minimization problems can therefore be written as probability-maximizing estimators for the expected value of data \(l_k=g(x,z_k)+\epsilon_k\) under the assumption of uncorrelated, normally distributed noise \(\epsilon_k\).